

一、安装VMWare
1.新建虚拟机
1.1 安装Linux操作系统
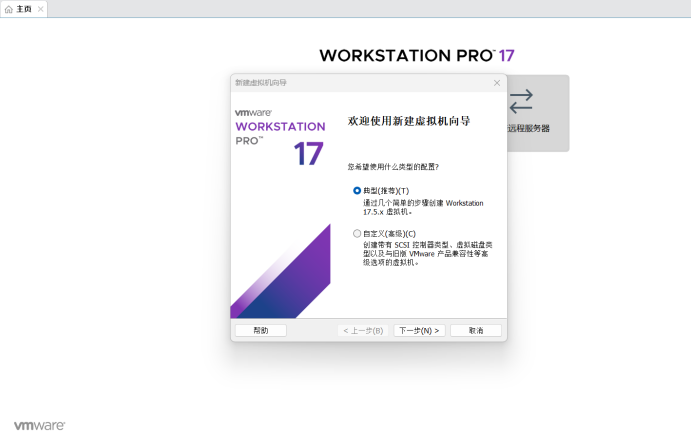
请进入Windows系统,启动VMware软件,按照以下两大步骤完成Linux系统的安装:首先需要创建一个虚拟机,然后,在虚拟机上安装Linux系统。打开VMware,在“主页”选项卡中,可以看到如图的界面,点击“创建新的虚拟机”。

在出现的界面中(如图所示),选择“典型(推荐)(T)”。
二、在VMWare安装CentOS 7
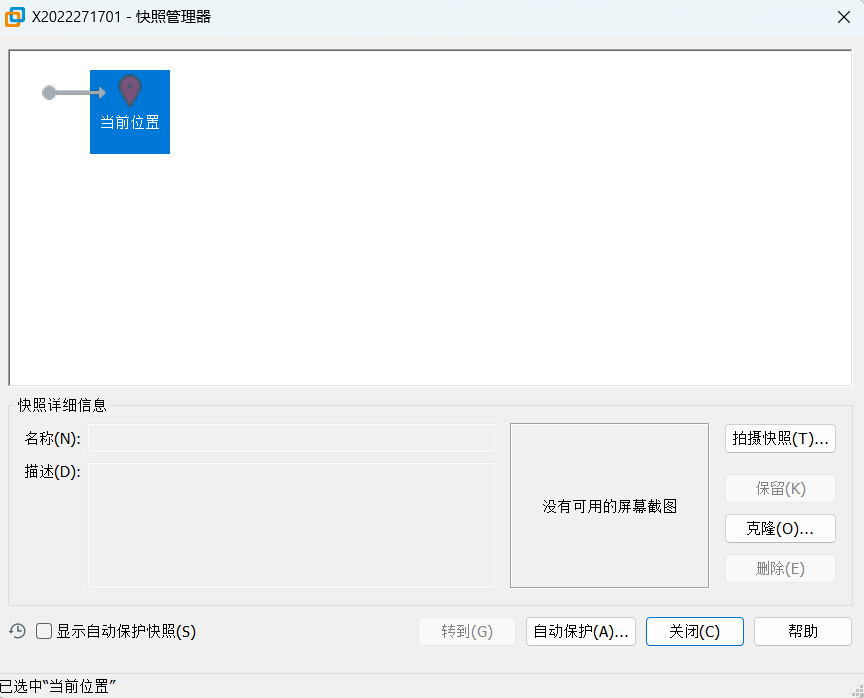
建议大家在安装之前给正常的操作系统做个快照
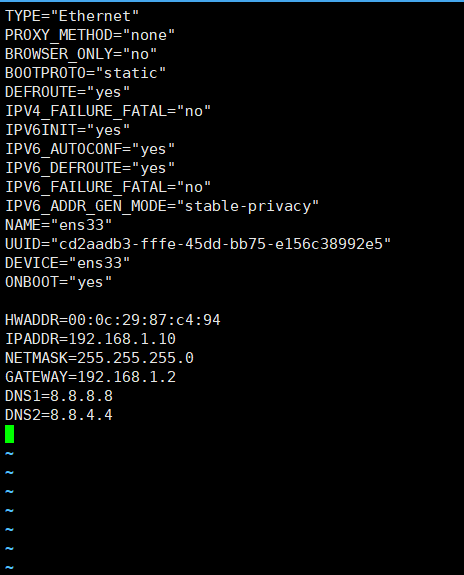
三、ip设置为手动的 ip a
五、确保网络可以ping通
六、mobaXterm终端软件
用来连接并管理服务器。解压缩文件到某个文件夹。双击使用。
七、创建ssh终端,要求使用root登录
八、修改网络配置文件
vim /etc/hosts
把ip地址和hadoop0名字加到配置中
192.168.1.10 hadoop0
其中192.168.1.10替换成你自己的虚拟机服务器的ip地址。测试方法:ping hadoop0
九、把jdk压缩包上传到服务器 /opt/software
这里以 /opt/software/为例 也可以自己找个文件夹存
十、解压,进入到/opt/software这个文件夹
解压 tar -zxvf jdkxxxxxx.tar.gz,会获得一个新的文件夹jdk1.8xxxxx
十一、把jdk1.8xxx这个文件夹移动到/usr/local
并且改名为jdk,命令:mv jdk1.8xxxxx /usr/local/jdk
十二、配置参数:vim /etc/profile
增加两个参数
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
十三、启用该配置文件 source /etc/profile
测试java版本java -version 显示如下: java version "1.8.0_212" Java(TM) SE Runtime Environment (build 1.8.0_212-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
十四、关闭防火墙自动启动
setup 上下键选择,回车键确认。Tab键跳转操作,空格键选中。 System services->firewalld.service->空格取消* ->回车->Quit
十五、关闭当前防火墙
systemctl stop firewalld
可以通过命令行systemctl status firewalld来确认。dead
十六、设置selinux的安全策略
vim /etc/selinux/config
修改参数:SELINUX=disabled
十七、免密登录:
生成密钥 ssh-keygen -t rsa
ssh-keygen -t rsa
回车3次
十八、进入~/.ssh文件夹
cd ~/.ssh
十九、生成对应的验证key
cat id_dsa.pub >>authorized_keys
二十、免密登录测试
ssh hadoop0
exit
二十一、上传大数据安装包压缩文件 上传到/opt/software文件夹
hadoop-2.7.7.tar.gz
二十二、进入到/root/Downloads,解压
tar -zxvf hadoopxxxxxxx.gz
二十三、拷贝解压后文件夹到/usr/local,并且改名为hadoop
mv hadoopxxxxxx /usr/local/hadoop
二十四、修改/etc/profile参数
vim /etc/profile
修改两个参数
export HADOOP_HOME=/usr/local/hadoop #新增
export PATH=$JAVA_HOME/bin
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
二十五、启用配置,让其生效。
source /etc/profile
二十六、修改hadoop的参数
hadoop参数是放在/usr/local/hadoop/etc/hadoop
cd /usr/local/hadoop/etc/hadoop
二十七、vim hadoop-env.sh
环境变量
export JAVA_HOME=/usr/local/jdk
二十八、vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000/</value>
<description>NameNode URI</description>
</property>
</configuration>
二十九、vim hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop0:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop0:50090</value>
</property>
</configuration>
三十、vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
三十一、vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0:8025</value></property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0:8050</value>
</property>
</configuration>
三十二、初始化节点
hadoop namenode -format
三十三、启动大数据服务器
start-dfs.sh
检测:jps 60963 Jps 60667 DataNode 60541 NameNode 60831 SecondaryNameNode
start-yarn.sh
jps 61297 NodeManager 61425 Jps 61027 ResourceManager 60667 DataNode 60541 NameNode 60831 SecondaryNameNode
三十四、浏览器访问虚拟主机的:
[hadoop0:50070]
三十五、正常关闭
stop-yarn.sh
stop-dfs.sh
poweroff

评论